Introduction
While reading an article about Physical and Logical Structure of PDF Files on Didier Stevens's blog, I came across an interesting puzzle. You can download the file to follow along or read the writeup from the author itself.
Challenge Analysis and Testing
Still here, great! Let's get started. First thing is to check what exiftool has to tell us about this file:
$ exiftool pdf-puzzle.pdf
ExifTool Version Number : 9.46
File Name : pdf-puzzle.pdf
Directory : .
File Size : 1243 bytes
File Modification Date/Time : 2014:09:18 17:00:16+05:30
File Access Date/Time : 2014:09:18 17:00:19+05:30
File Inode Change Date/Time : 2014:09:18 17:00:16+05:30
File Permissions : rw-rw-r--
File Type : PDF
MIME Type : application/pdf
PDF Version : 1.1
Linearized : No
Page Count : 1
All these attributes look standard and nothing suspicious pops out in the output. The author, Didier Stevens, hints that it is a simple challenge and can be solved using just Notepad or a standard PDF reader. Let's view contents of this file in a text editor:
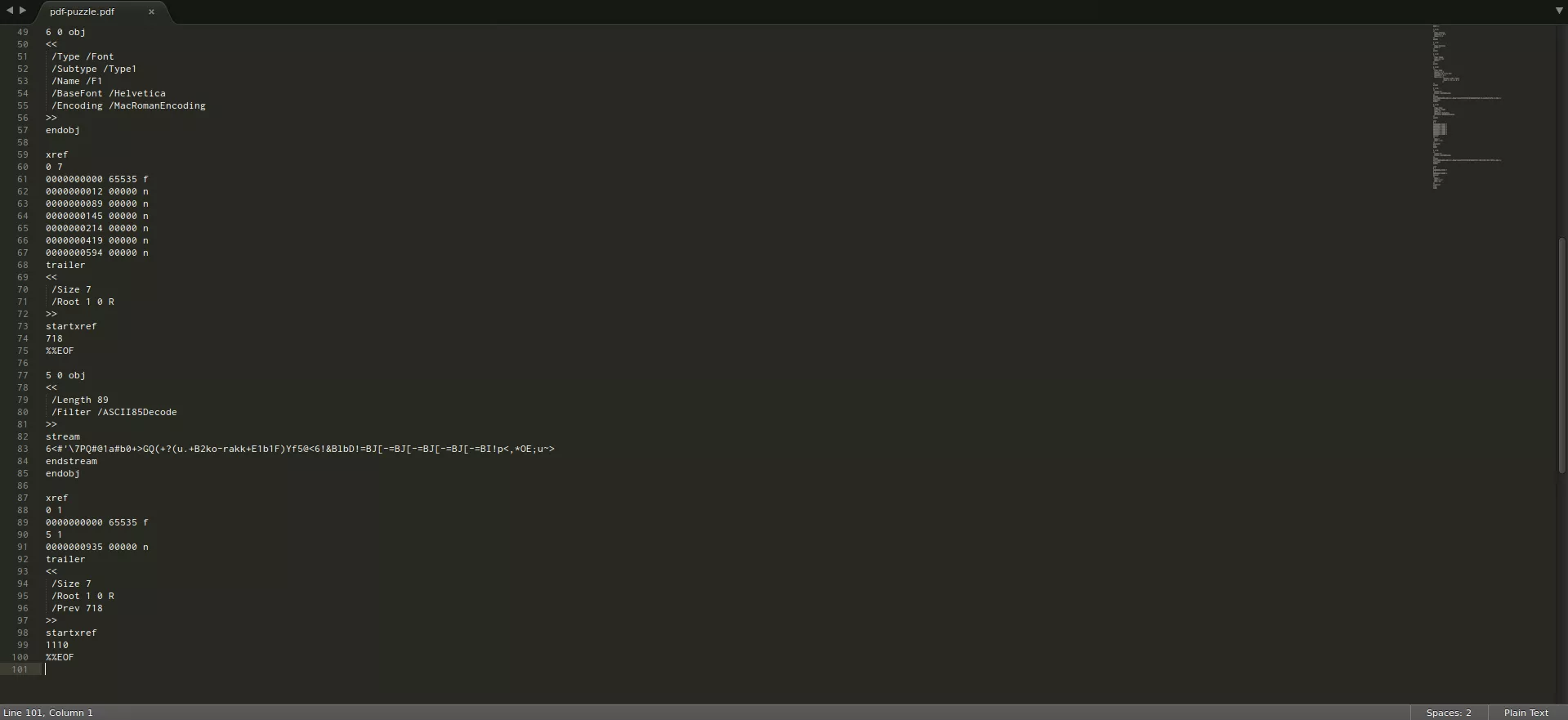
If you have not read Didier Stevens's Physical and Logical Structure of PDF Files post I strongly recommend reading it before reading further. It will help you identify something out of the ordinary in above output. There are two copies of xref table and trailer in this file hinting that it is probably a PDF with Incremental Updates. The new content (after the first %%EOF) has redefined object 5 and updated the xref table to help renders know its new offset. If you open this file in a PDF viewer, you will see something like this:

The reader is using updated object and renders its content, thus overriding the older object definition. Since both object definitions contain ASCII85Decode encoded streams, we can manually decode and look at the raw content:
$ ipython --no-banner
>>> import ascii85
>>>
>>> ascii85.ascii85decode("'\7PQ#@1a#b0+>GQ(+?(u.+B2ko-rakk+E1b1F)Yf5@<6!&BlbD!=BJ[-=BJ[-=BJ[-=BJ[-=BI!p<,*OE;u~")
'\x14h\xd5"4 Tf 100 700 Td (The passphrase is XXXXXXXXXXXXXXXXXXX) Tj ET'
>>>
>>> ascii85.ascii85decode("'\7PQ#@1a#b0+>GQ(+?(u.+B2ko-rakk+E1b1F)Yf5@<6!&BlbCgDI[]uD.RU,@;I&dE+EC!ATK:C<,*OE;u~")
'\x14h\xd5"4 Tf 100 700 Td (The passphrase is Incremental Updates) Tj ET'
>>>
Conclusion
Awesome! The older object stream, when decoded (I'm using the ascii85 decoder from pdfminer), shows the passphrase. As suggested by Didier Stevens in his writeup, you could also remove the updated object content and xref table from the file to view the passphrase.